
世界杯最新消息Position
你的位置:2026世界杯中国最新押注app > 世界杯最新消息 > 2026世界杯最新押注登录平台 Meta蔡志鹏新作VLM³: 全面揭示三维视觉的Bitter Lesson
发布日期:2026-06-14 15:34 点击次数:64


蔡志鹏博士(https://zhipengcai.github.io/)是好意思国 Meta 公司的高档询查员,博士毕业于澳大利亚阿德莱德大学。他的询查主要围聚在 Physical Intelligence,包括三维视觉、多模态大模子等。他的责任已在领域顶级会议杂志上发表跨越 20 篇。其中 10 篇著作被选为顶级会议表面或特邀讲演,对鲁棒推断计较复杂度的表面施展责任被选为 ECCV18 12 篇最好论文之一。
Meta 发布了一项令东说念主震荡的询查责任 VLM³,初度揭示了三维视觉学习的 Bitter Lesson:程序的视觉讲话模子 + scale 数据就是最浮浅灵验的范式,针对特定任务的架构、亏空函数以及数据增强的缠绵,以致是 regression 的 formulation,均不是三维视觉学习的必要要求。

现时的视觉讲话 AI 模子(Vision Language Models, VLMs)通过斡旋的模子架构大概生动解决各种不同的视觉任务。连系词,尽管在语义交融、视觉问答、图像提醒等任务上阐扬优异,它们在三维视觉方面仍然阐扬欠安。比较之下,群众视觉模子(expert vision models)在完全深度推断(metric depth estimation)等三维交融雇务上,凭借特意缠绵的网罗结构、亏空函数及数据增强,还是达到了卓越东说念主类的精度。
这就带来了一个中枢问题:「视觉讲话模子是否在三维视觉学习方面无法替代群众模子?」VLM³ 初度施展了该问题的谜底是抵赖的!
VLM³ 通过极简的缠绵,在极为各类的三维视觉任务中忘形或卓越群众视觉模子,2026世界杯预选赛下单中国体彩官网并大幅卓越发轫进的视觉讲话模子:1)在单目深度推断上 match UnidepthV2 及 MoGe2;2)在方针级三维交融雇务上卓越 SpatialRGPT;3)在像素匹配任务上卓越 DKM 和 RoMa;4)在相机姿态推断上 match DA3,卓越 VGGT。

代码地址:https://github.com/facebookresearch/VLM3
二、亮点
在此之前,即即是发轫进的 VLM 在程序的三维视觉任务中均远远逾期于群众视觉模子。
VLM³ 通过详备的实验发现,程序的 VLM 仅需要 1)相机焦距归一化;2)像素空间归一化,就大概以令东说念主咋舌的爽气阵势灵验学会各种三维视觉模子,在 1)单目深度推断中 match UniDepthV2 及 MoGe2;2)在方针级别三维交融卓越 SpatialRGPT;3)在像素匹配任务上卓越 DKM 和 RoMa;4)在相机姿态推断上 match DA3 并卓越 VGGT。
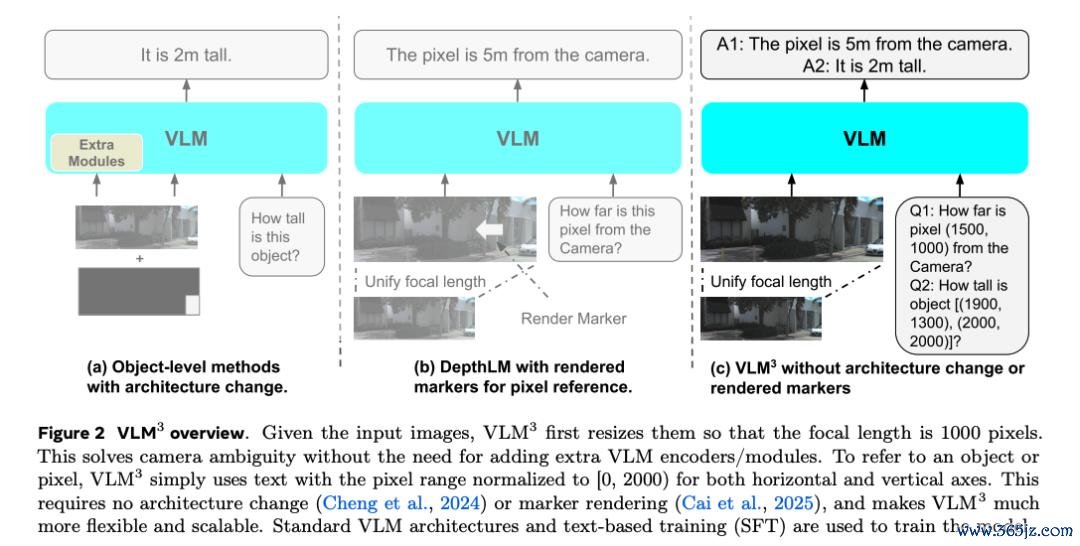
和之前的三维视觉 VLM 不同,VLM³ 既不需要更正 VLM 的架构,也不需要在图片上渲染 marker。比较于群众视觉模子需要多数的架构、亏空函数及数据增强方面的复杂缠绵,2026世界杯最新押注登录平台VLM³ 仅需要程序的 VLM 架构(如 Qwen3-vl-4B)和考验(基于笔墨的 SFT)就大概在极为各类的三维任务上达到 SOTA。
这种爽气的考验推翻了之前三维视觉的学习范式,并揭示了三维视觉的 Bitter Lesson:咱们其实完全不需要针对特定三维视觉任务东说念主为缠绵复杂的架构、亏空函数及数据增强。通过浮浅的视觉讲话建模 + scale 数据就大概达到不异的遵循,况兼于其他非三维视觉任务在斡旋的讲话模子考验框架下完全兼容。这使得三维视觉不再需要与视觉讲话模子的大规模预考验分别,同期咱们大概使用不异的阵势来休止三维视觉的 scaling law。
开云体育app2026世界杯中国官网下载同期 VLM³ 的得手也意味着三维视觉的学习远比咱们思象中的要容易:除开不需要异常架构、亏空函数等,咱们以致不错不依赖回来(regression)来学会 fine-grained 3D understanding,这在之前的责任中是难以思象的,因为在知晓的输出空间进行回来是绝大多数三维视觉模子的中枢缠绵。
三、主要戒指 / 性能对比
在四大三维视觉任务上性能显赫优于发轫进的 VLM
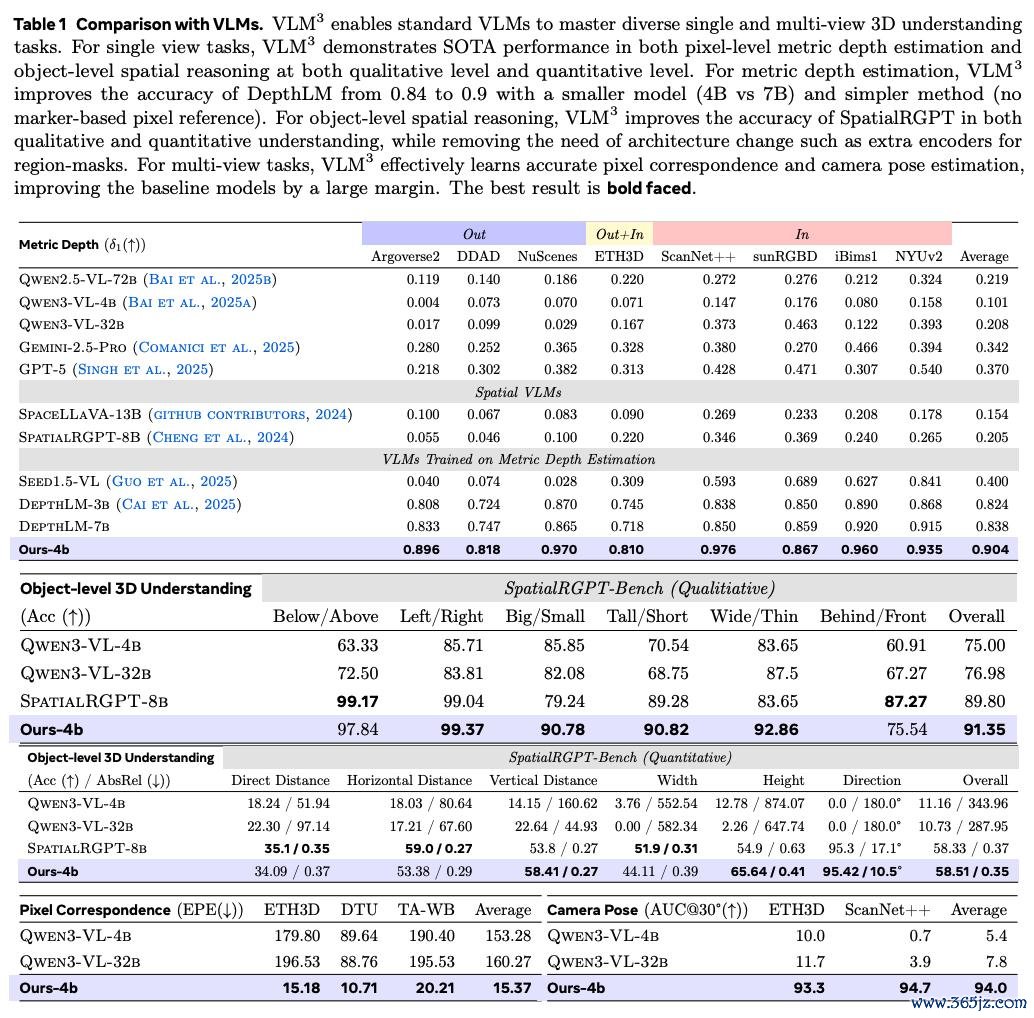
在单目深度推断上将 DepthLM 的准确率从 84 进步至 90,况兼考验及推理愈加浮浅高效,无需渲染 marker。
在方针级别三维交融上用不异的考验数据卓越 SpatialRGPT,况兼无需迥殊的 encoder,模子参数少一半(4B vs 8B)。
在多视角几何任务上如像素匹配及相机姿态推断上远超 Qwen3-vl-32B。
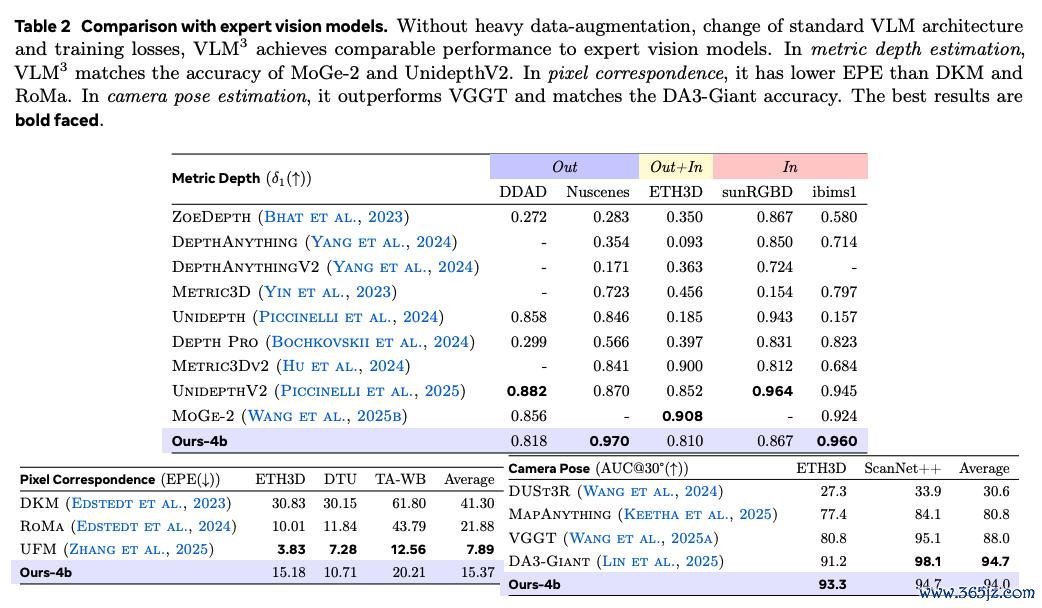
同期在与先进的群众视觉模子(如 MoGe2、DA3、RoMa 等)的对比中,VLM³ 也绝不失态,况兼完全不需要复杂的架构、亏空函数及数据增强。

四、意旨 / 利用出路
VLM³ 从头界说了三维视觉的最勤学习范式:最浮浅的 generalist 架构如 VLM 及 scaling 就是最通用的三维视觉范式!已往三维视觉领域广宽吸收的东说念主为的 task-specific 的缠绵并非必须。
这将极猛经由地简化三维基础模子的构建。通过将三维视觉任务融入视觉讲话模子的预考验,咱们也能灵验地兼容三维视觉与其它视觉任务,并将 VLM 的上风,及生动性与泛化性从语义及二维视觉任务灵验拓展至三维视觉,极猛经由进步模子的才智上限。
结语
VLM³ 的出现,初度买通了视觉讲话模子与三维视觉之间的壁垒2026世界杯最新押注登录平台,使得斡旋的架构就大概爽气地学会各种视觉任务,并达到群众模子的性能。这既是科研层面的里程碑,也为明天在内容系统中斡旋多模态推理才智提供了可能。咱们期待 VLM³ 后续在机器东说念主、自动驾驶、增强本质等场景中的落地利用。
 备案号:
备案号: